Gemini Models: Pro, Flash, and Flash Lite
Modern releases differ in reasoning depth, speed, and operational price, and these dimensions determine whether a workflow remains experimental or becomes production grade.
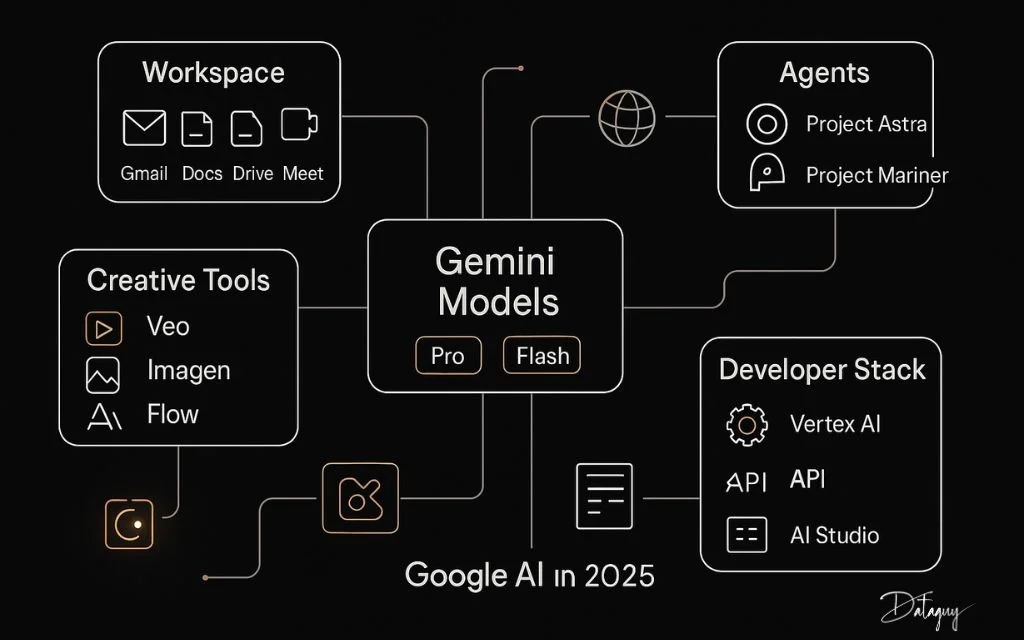
Google AI in 2025
Developers who understand the intention behind each model family can combine them intelligently, assigning heavier intelligence where necessary while delegating repetitive or high volume operations to lighter and faster variants. The descriptions below outline how the currently available tiers are typically used in practice, what advantages they emphasize, and how organizations align them with real world objectives.
These Models can be accessed through the Gemini API:
Latest Models:
Gemini 2.5 Pro Best for complex reasoning and high stakes applications.
Gemini 2.5 Flash The default choice for most applications, balancing speed and intelligence.
Gemini 2.5 Flash Lite Optimized for scale and cost efficiency in routine tasks.
Older Models:
Gemini 2.0 Flash
Gemini 2.0 Flash Lite
Gemini 2.5 Pro
Gemini 2.5 Pro represents the high end of the spectrum. It is built for demanding scenarios in which subtle reasoning, advanced logic, or deep contextual interpretation is central to success. When tasks involve ambiguity, technical rigor, or multi step intellectual work, Pro often demonstrates greater consistency and sophistication. Analysts may prefer it for complex policy evaluation, scientists for theoretical exploration, and senior writers for nuanced argument development.
However, these strengths come with tradeoffs. Pro is typically slower than Flash and incurs higher cost per token. Therefore it is rarely used indiscriminately. Mature organizations route only the most challenging components of their pipelines to Pro while allowing lighter models to handle preparation and formatting. This selective escalation ensures that the budget is spent where additional cognition truly matters.
Pro also tends to be valuable when reputation or compliance risk is present. If the generated material will influence decision making, legal interpretation, or public communication, stakeholders often accept the extra cost in exchange for improved reliability. In that sense, Pro functions as a precision instrument rather than a mass production engine.
Gemini 2.5 Flash
Gemini 2.5 Flash has become the default recommendation for a large majority of applications because it strikes a rare balance between capability and efficiency. It is designed to be fast enough for interactive systems while still providing reasoning quality that satisfies academic, professional, and enterprise expectations. In many deployments it supports extremely large context windows, enabling it to read books, research archives, lengthy reports, or collections of profiles without requiring aggressive chunking strategies. This dramatically simplifies engineering complexity and reduces the need for elaborate pre processing pipelines.
In everyday practice, Flash performs strongly across drafting, summarization, transformation, and general knowledge tasks. Universities may use it to produce lecture materials, startups might integrate it into customer support automation, and researchers frequently rely on it for literature condensation or idea exploration. The speed profile makes it suitable for workflows where humans remain in the loop and expect quick responses. At the same time, its intelligence level is high enough that outputs rarely feel superficial.
Another major benefit of Flash is economic predictability. Because it is not priced like the premium reasoning tier, teams can run significant volumes without fear of runaway bills. This encourages experimentation, iteration, and continuous integration into digital products. As a result, many architects define Flash as the baseline model and evaluate alternatives only when there is clear evidence that additional intelligence or lower price is essential.
Gemini 2.5 Flash Lite
Gemini 2.5 Flash Lite is optimized for scale. It aims to deliver useful intelligence at the lowest feasible price, enabling organizations to process extraordinary volumes of material. While it may not match the nuanced reasoning of Flash or Pro, it remains more than capable for routine or structured tasks. Examples include classification, short summaries, tagging, metadata extraction, templated rewriting, and preparatory transformations before human review.
The presence of Lite allows architects to design tiered systems. Large datasets can first be normalized or filtered economically, and only the most relevant or complex portions are then escalated to more capable models. This approach mirrors traditional computing hierarchies in which expensive resources are reserved for the moments when they are indispensable.
Because of its affordability, Lite often becomes central in educational technology platforms, content management systems, and monitoring pipelines. Continuous processing that would otherwise be financially prohibitive becomes realistic, opening opportunities for automation at unprecedented scale.
Gemini 2.0 Flash
The Gemini 2.0 Flash family continues to appear in many environments primarily due to compatibility and historical adoption. Although its capabilities remain solid, it generally reflects earlier tuning and smaller output limits compared with the 2.5 generation. Teams maintaining legacy integrations may find stability in continuing to use it, especially if their performance requirements are already satisfied.
For new systems, however, migration toward the more recent models usually yields improvements in reasoning quality, context handling, and future support. Over time, maintaining older tiers can limit access to advancements that simplify development or enhance results. Therefore 2.0 Flash is best viewed as dependable but gradually being superseded.
Gemini 2.0 Flash Lite
Gemini 2.0 Flash Lite follows the same philosophy as its 2.5 counterpart but within the earlier generation. It provides economical processing and is frequently embedded in pipelines where cost containment is paramount. Organizations that built infrastructures around this model may continue to operate efficiently, yet they might consider evaluating newer alternatives to capture gains in performance and token allowances.
Despite being older, it still supports a broad range of lightweight applications. For some workloads, especially those with tight formatting or predictable patterns, differences between generations may not materially affect outcomes. In such cases, stability can outweigh the incentive to upgrade.